This class supports the construction of a light weight in memory tree from an XML file. Like the W3C DOM Document object, the structure of this tree reflects the structure of the XML.
The tree that is constructed is designed for rapid traversal and in memory modification. It also has the advantage of using less memory than the java.sun.com DOM Document implementation.
This code demonstrates how little source code is required to parse XML using the XmlPullParser.
A few notes about attributes and namespaces. In general I think that the XmlPullParser rocks. The API is will designed and the calls mostly make sense. But... the XmlPullParser does not treat all attributes the same way. In particular it does not treat name space definitions like other attributes. This can be seen in XML designed to be processed via a schema. For example:
<ex:EXPRESSION
xmlns:ex="http://www.bearcave.com/expression"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.bearcave.com/expression xmlexpr/expression.xsd">
Here there are two name space definitions. One defining the namespace associated with the "ex" prefix and one associated with XML schemas (for the schema location attribute).
The getAttributeCount() method will return 1 when processing the EXPRESSION tag. This is because the name space definitions (the attributes with the xmlns prefix) are not treated as normal attributes. And sometimes this is good, because these attributes are not necessarily of interest. In this case, however, the intent is to exactly mirror the XML in an in-memory tree. So that if the tree is serialized the original XML will be recovered (with the exception of white space TEXT, since this is not included).
The attributes are only available when the END_TAG element for the document tag is processed. The getDepth() method tells the current XML nesting depth, so it can be determined that an END_TAG is the document end tag. The attributes are then fetched and prepended to the attribute list. Sort of awkward. This is the one place where I would differ in the design of the XmlPullParser. I'd treat all attributes the same way, including those with the "xmlns" prefix. Then the user can simply ignore operands with the namespace prefix.
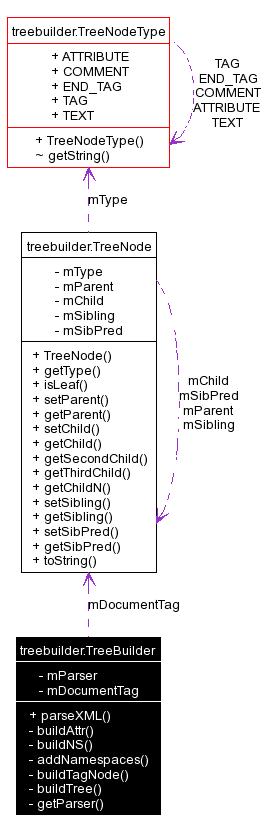
Public Member Functions | |
| TreeNode | parseXML (FileReader reader) throws XmlPullParserException, IOException |
| This is the public entry point for the TreeBuilder. | |
Private Member Functions | |
| Attribute | buildAttr (int index) |
| Attribute | buildNS (int index) throws XmlPullParserException |
| void | addNamespaces (int depth) throws XmlPullParserException |
| This method is called for the end tag of the root document tag. | |
| TagNode | buildTagNode () |
| Build a tag node. | |
| TreeNode | buildTree () throws XmlPullParserException, IOException |
| Recursively parse an XML file into an in-memory tree data structure. | |
| XmlPullParser | getParser () throws XmlPullParserException |
| Allocate and initial an XmlPullParser. | |
Private Attributes | |
| XmlPullParser | mParser = null |
| TreeNode | mDocumentTag = null |
|
|
This method is called for the end tag of the root document tag. If there are name spaces, they would have been defined in this tag. Insert them in the front of the attribute list.
|
|
|
|
|
|
|
|
|
Build a tag node. Note that a tag node always has an AttributeList object, even if there is no attribute list. This wastes some memory, but in theory should make the tree processing more regular, since it can always be assumed that this object exits.
|
|
|
Recursively parse an XML file into an in-memory tree data structure. Currently this code only handles the COMMENT, TEXT and START_TAG elements returned by the XmlPullParser. Other XML elements are ignored.
|
|
|
Allocate and initial an XmlPullParser. At the time this code was written the XmlPullParser did not support validation, so the call to setValidating() is passed "false".
|
|
|
This is the public entry point for the TreeBuilder. It is passed a FileReader, which has been opened for an XML file.
|
|
|
|
|
|
|
 1.3.8
1.3.8