Figure 1
The DOMParser is probably the most commonly used Java object for reading and validating XML documents. The DOMParser reads the XML and (depending on the parser initialization) will validate the XML against an XML schema. If the XML is valid, the DOMParser will return a Document (DOM) object, which represents the XML as a tree structure. The XML can be processed by walking this tree. An example of how the DOMParser can be applied to processing arithmetic expressions in XML format is discussed on a companion web page.
Building a DOM object is relatively processor intensive and the resulting DOM object consumes a relatively large amount of memory. For large XML documents the memory and processor resources consumed can be prohibitive. The SAX parser is sometimes used to process large XML documents. Like the DOMParser object, the SAXParser object can validate XML against an XML schema. However, the SAXParser is faster (at least when validation is turned off) and uses less memory than the DOMParser. Unfortunately, the SAXParser is poorly designed. Rather than being called by the parsing application, the SAXParser uses a message handler with "call backs". In effect, the HTML scanner/parser calls the parsing application. The SAXParser design is, to but it bluntly, "ass backward".
Sometimes when I try to explain to people why the SAX approach to parsing is poorly designed, I get a blank look. People without a background in language processor implementation do not always understand why the approach taken by the SAXParser makes the software architecture much more difficult than it needs to be. Or if they do understand, they do not know of an alternative to the SAXParser. The objective of this web page is to show that there is an alternative to the SAXParser (the XmlPullParser) and that this alternative simplifies the software architecture.
I've chosen a relatively simple XML translation application to compare the SAXParser and the XmlPullParser, since the awkward architecture that the SAXParser imposes on an application frequently limits it to simple applications. The prototype application that I've used to compare the SAXParser and the XmlPullParser involves processing XML formatted messages for a trade engine. This simple application is described on the related SAXParser web page.
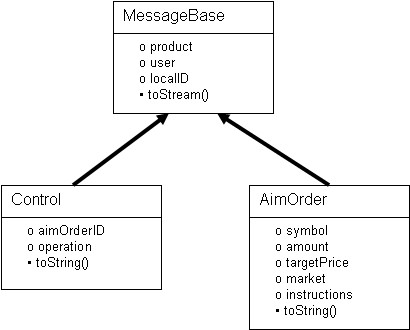
All trade engine messages share a common base class that contains field that are shared by every message. As Figure 1 shows, the specific messages are derived from this base class.
Figure 1
Where the SAXParser required a message handler class hierarchy that mirrored the data class hierarchy, the XmlPullParser allows each data class to be extended with an initialize() method that is passed the XmlPullParser. This is shown in the Doxygen generated UML diagram in Figure 2.
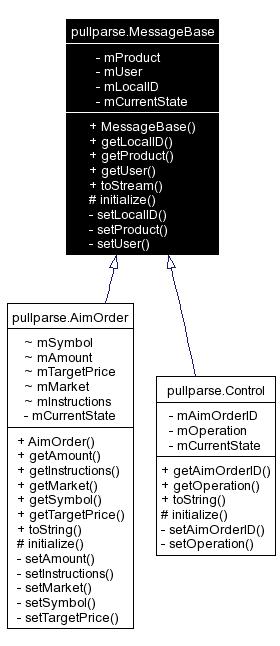
Figure 2
The version of the XmlPullParser distributed by the University of Indiana Extreme! Computing Group does not support validation of an XML document against and XML Schema.
It is pretty clear what validation means in the case of the DOMParser: the XML document is verified against the XML Schema. If the XML document is valid, a Document object, that represents the XML document as a tree, is returned.
The SAXParser also seems to support validation. However, unlike the DOMParser, which returns a representation of the entire document, the SAX parser reads the document incrementally, invoking the call back functions of the document handler as it goes. What level of validation is being performed by the SAXParser in this case is unclear, at least to me.
Referring to the SAXParser or the XmlPullParser as parsers is really a misnomer. They are, in fact, what compiler design text books describe as a scanner. A scanner returns the tokens of a language (in this case XML). These tokens are processed by the parser, which has information about the syntax. The only real "parsing" that the SAXParser or the XmlPullParser do is to assure that the XML document is propertly formed.
If we recognize that the XmlPullParser is really a scanner (and use it as a scanner) then the fact that it does not perform XML Schema validation is not problem. In applications where complex validation is required the XmlPullParser can be used as a scanner for a parser generated by a tool like ANTLR or JavaCC. These parsers are generated from a grammar. When an XML document that differs from this grammar is processed by the parser, an error will be reported.
The source code for this XmlPullParser based prototype application can be downloaded in either "tar" or "jar" format:
To unpack these files use either:
tar xvf pullparse.tar
jar xvf pullparse.jar
The pullparse classes use the TypeSafeEnum classs. The TypeSafeEnum class is discussed on this web page.
Doxygen formatted documentation for the pullparse classes can be found here.
XmlPullParser web page at xmlpull.org
The XmlPullParser was originally written by Stefan Haustein and Aleksander Slominski. Aleksander Slominski appears to be the person who is currently leading the project. Apparently this page publishes the XmlPullParser (XPP), version 2. Version 3 (XPP3) is published on a University of Indiana web page (see below).
A 3ed Generated XmlPullParser: The XML Pull Parser Web Page at the University of Indiana
The University of Indiana Extreme! Computing Lab publishes the web page above. Apparently Aleksander Slominski is part of the Extreme! Computing lab group. This web page publishes version 3 of the XmlPullParser.
Instructions for downloading the source (via anonymous CVS checkout) and Java ".jar" files can be found on this web page.
The University of Indiana Extreme! Computing lab allows distribution and use of the software as long as it includes their copyright: Copyright (c) 2002 Extreme! Lab, Indiana University. All rights reserved and acknowledges their authorship:
This product includes software developed by the Indiana University Extreme! Lab (http://www.extreme.indiana.edu/).
The LICENSE.txt file is part of the CVS source code download.
To build the software published on this web page (or your own software using the XmlPullParser) you will need the XmlPullParser "jar" files. You can do what I did: checkout the Java source from CVS and build the "jar" files by running the "Ant" script, or you can download the files here. In the XmlPullParse version I used there were three "jar" files:
xpp3-1.1.3.4.H.jar xpp3_min-1.1.3.4.H.jar xpp3_xpath-1.1.3.4.H.jar
You can download these files in either "zip" or "tar" format:
Building and Processing XML in Java
This web page publishes Java source code that demonstrates how to build XML Document objects. It also publishes code that shows how to parse, validate and process XML. An XML Document object is build from an arithmetic expression or assignment statement (e.g., x = 3 + 4 * 5). The resulting XML Document is then "serialized" to a String object. The String is then read by an XML parser, validated and convered to an XML DOM object. The DOM tree is traversed and the expression (or statement) is evaluated). The XML construction and evaluation objects are used to construct an interactive expression processor.
The DOMParser and the DOM object it builds are useful for processing complex XML documents. However, DOM may impractical for very large XML documents because of its memory use. Also, the construction and traversal of a DOM object has a computational cost.
The SAXParser is an alternative to the DOMParser. This web page publishes example SAXParser code that processes prototype messages that might be used a Trade Engine, a software system that supports computer driven trading.
Building an in-memory tree with the Xml Pull Parser
This web page publishes a remarkably small object that builds an in-memory tree representation of an XML document using the XmlPullParser. A tree-to-XML serializer is also included.
Design of a Pull and Push Parser System for Streaming XML by Aleksander Slominski
The Streaming API for XML (StAX) is a Java based API for pull-parsing XML
This is a Java Community Process "specification" for XML Pull Parsing. The final release is dated March 25, 2004. BEA Systems seems to claim rights to this API and its implementation:
BEA Systems, Inc. ("BEA") grants you a non-exclusive and non-transferable license for the internal use only of the accompanying software and documentation provided by BEA for the Streaming API for XML ( the "Software"), including, but not limited to the right to reproduce and use the Software internally for the purpose of testing an implementation of the JSR-173 specification.
Sun Java Streaming XML Parser, Stax (JSR 173) implementation
This is Sun's release of an XML Pull Parser. One attractive feature is that it not only includes a parsing interface, but also XML construction interface. This may make it more attractive than XML pull when it comes to parsing and rewriting XML. This may also have been released as part of Sun's Java Web Services Developer Pack
VTD stands for Virtual Token Descriptor. This is a compact (or one could almost say compressed) format for representing XML trees in memory. The authors write that the in-memory footprint is 1.3 to 1.5 times that of the XML document making it much less memory intensive than DOM. They also write that the speed of processing is similar to that of SAX. Both C and Java versions are available.
Ian Kaplan, August 2004
Revised: January 2006
